Can AI Agents Actually Learn to Trade?
In this blog post, we outline the details of our recent research paper, in collaboration with the Barclays CTO office. To learn more about how we use model discovery in our agentic workflows, sign up to our Simudyne Horizon waiting list here.
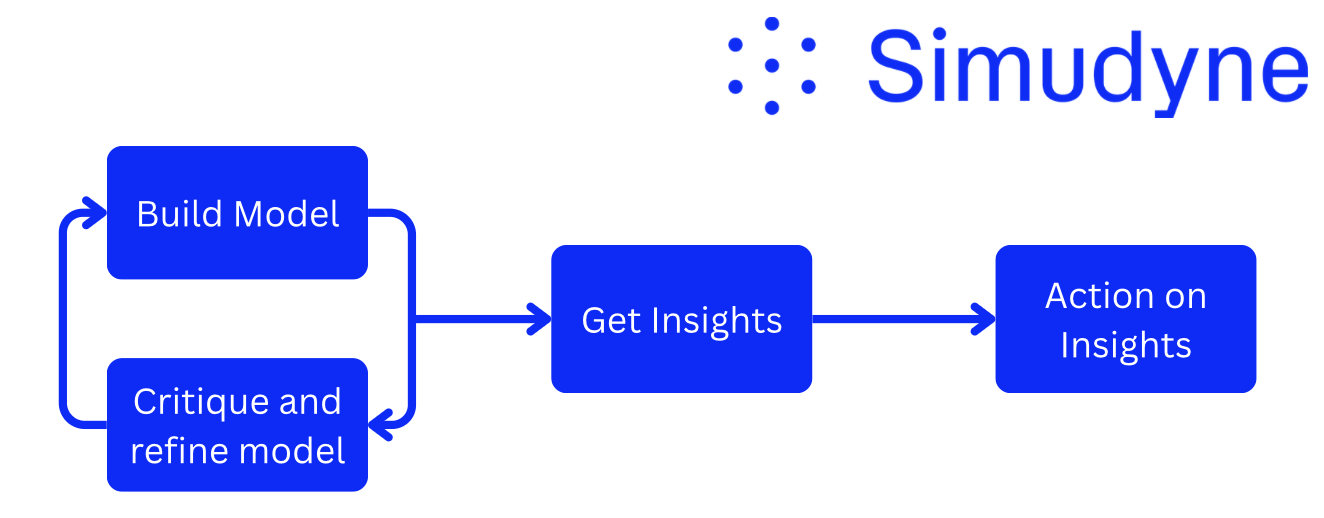
Using agents is quickly becoming the most talked about thing in 2026. These agents are being used for daily tasks and everyone is looking to “optimise workflows” or have “the robot” perform more of their tasks.
At Simudyne, we’ve known that agents can perform simple tasks to a high standard for some time. The next question for us has been how complex a task can they handle?
To find this out, we developed a process that results in agents autonomously making complex multi-stage decisions. When humans make these sorts of complex decisions, we often call it “instinct.” In reality, instinct is the result of an internal world model built over years of experience. Replicating that in AI is not straightforward.
LLMs show incredible aptitude at writing and debugging code. In addition, due to AI being trained on the internet, they have a very good idea about what humans find interesting, giving them strength in their ability to critique ideas. This means that we can use AI to build and refine models at a rapid rate, compressing years of model evolution into a short time span. We call this process model discovery.
The proposed agentic process is structured as several tasks (shown as the blue bubbles in Figure 1), where each task is composed of multiple specialised agents. We use these agents to build and refine a model of their environment. We refer to this environment as a “world view” (more on that in a second). From this “world view”, we then design our agents to derive actionable insights.
With this framework defined, we want to test this in a sufficiently complex environment. We chose to look at financial trading, which is stochastic, non-stationary and dynamic.
To Trade Or Not To Trade?
First, let’s establish what the “world view” is for financial trading. A world view is all of the data that is required for someone to perform an action. For example, in order for a thermostat to perform its action (regulating the temperature of a room), it needs to know the current temperature of the room. This is what we refer to as a “world view”.
For trading, we simplified this “world view” to two inputs:
- The current price
- Company news snippets
To implement this framework, we begin by discovering a model of the historical stock price. Using historical price data, the agent suggests, builds, and refines a stochastic model that approximates market behaviour. We refer to this process of model discovery.
We constrain the space of models to those that are stochastic. This allows us to sample hundreds of synthetic price trajectories that share structural characteristics with our model. Analysing these trajectories reduces noise sensitivity and enables the extraction of underlying risk and trend signals.
These signals are then combined with some analysis of recent company news and finally passed to a trading agent, which makes the final decision: Buy, Sell, or Hold. A schematic of this process is shown in Figure 2.
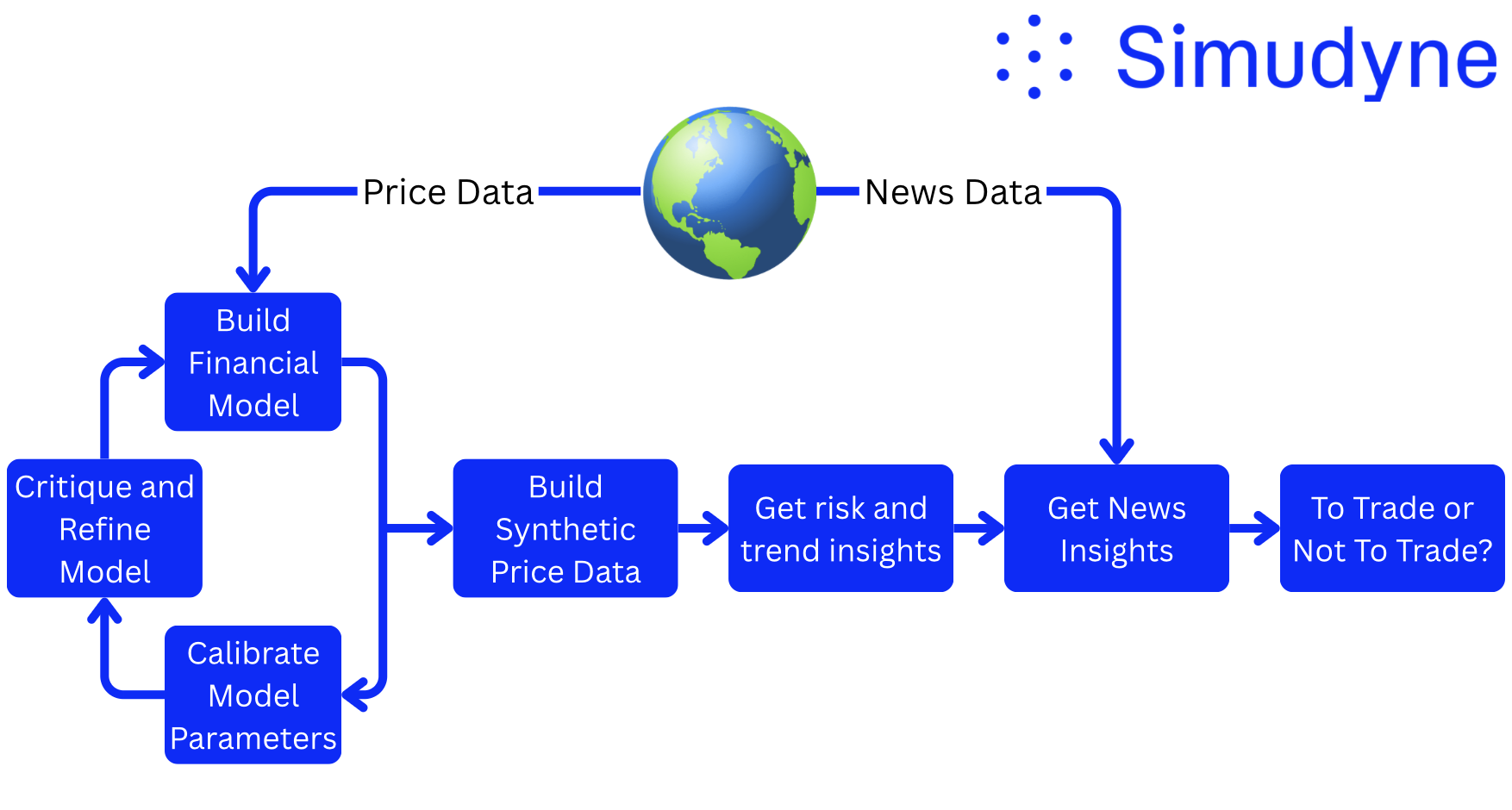
Each of these tasks (shown as the blue bubbles in Figure 2) are performed by a collection of agents. We go into more detail about how each task works below.
Task 1 — Financial Model Generation
First, we use agents to build a model of the financial market. The agent takes in the critique of the previous models (stored in our agentic memory base) and proposes a stochastic differential equation (SDE) to mimick the price evolution. This allows us to sample the stochastic component repeatedly and generate multiple plausible price trajectories.
SDEs are foundational in quantitative finance for modelling the evolution of asset prices, interest rates, and volatility, which are inherently uncertain. This is why we selected SDEs as a practical and interpretable scaffolding for our agents.
Task 2 — Calibration and Iterative Critique
These SDEs are written with parameters which need to be calibrated. The agent implements the model in JAX using the diffrax library, allowing rapid calibration of these parameters.
After calibration, our evaluated models fit using a range of statistical metrics. The model and its statistical metrics are then stored in memory. A separate agent analyses these outputs to produce a structured critique. This critique is then passed back to the builder agent to design an improved model. The process iterates until convergence, defined by the model fitting the price data to within a predefined threshold.
Task 3 — Monte Carlo Risk & Trend Extraction
Now that we have a model of our market we can use this to generate synthetic price paths (through Monte Carlo sampling) and get a diverse view of the current market state.
These Monte Carlo simulations are used to generate risk and trend metrics for that particular symbol. This is one of the key insights passed to the trader to make their decision.
Task 4 — Balanced News Analysis
Two separate agents were tasked to read news headlines about the company in question and produce either a bullish or bearish summary. This was to get a view of the news cycle which is equally positive and negative to help give the trader a balanced view.
This was the second key insight passed to our trader agents.
Task 5 — Trading Decision
Finally, our trading agents were given the insight metrics and the news analysis and told to make a simple decision: Buy, Sell or Hold. The agent was also tasked to give a reasoning output to help the interpretability of the output. It generated this decision decision daily.
Results
We designed this paper as a benchmarking exercise for frontier LLMs. We wanted to assess several key skills all combined into one task. The specific skills include code writing, model suggestion, novelty, semantic analysis, summarisation and decision making. Our key results were as follows:
Firstly, we found that Anthropic’s Sonnet 3.7 was the best model builder, making the most diverse suggestions while also being able to actually implement these in code without significant errors.
Secondly, we found that Llama 3.3 gave the most diverse and interesting model suggestions but unfortunately lacked the coding ability to actually build these complicated models so they would run without human input.
Thirdly, we found that the LLMs which built comparatively worse SDE models (quantified using the goodness of fit metrics) also performed worse in terms of profit. This shows that bad models will result in bad results and great care should be taken to ensure the best model is generated.
We also performed an ablation study where we assessed the trader agent with and without the SDE derived insights. We found that on average, when the trader agent was given these insights, the trader agent performed better. This shows that the model building and refinement step were crucial to the trader eventually making profitable decisions. This reinforces the title of our paper; ‘An Agentic Approach to Estimating Market Risk Improves Trading Decisions’.
The key question: is it profitable? The short answer is… maybe. Although some LLMs were consistently profitable, the test was not conducted at sufficient scale to draw firm conclusions about profitability. We leave this exercise up to the reader.
Intelligent Back-Test
A major concern in LLM-based financial research is data leakage. When we conducted our experiments, we used historical backtesting rather than live deployment. This means that there is a risk that the models had already seen similar news events and corresponding price movements during training.
For example, events such as the NVIDIA crash following the DeepSeek announcement formed part of our test period and may plausibly exist within model training data.
To mitigate this risk, we used the Simudyne market simulator to construct a fully synthetic environment. We generated realistic price paths using a development version of Simudyne Horizon and paired this with causal scenarios.
When evaluated in this synthetic setting, the performance was worse, but the overall ability of the LLMs did not collapse. The agents remained profitable in the synthetic setting, but performance declined, with smaller and less consistent returns than in the historical backtest. This suggests that data leakage may influence these types of experiments and demonstrates the value of testing in synthetic environments.
Conclusion
Our key finding is that agentic model discovery processes can improve decision making. This paper presents a coordinated multi-agent model discovery process, with agents performing tasks such as modelling, calibration, critique, and decision making.
Overall, we found that the quality of decisions were directly connected to the quality of the model discovered by the AI. Mathematical models that better fit historical data produce more accurate representations of the market’s underlying dynamics, which in turn generate more reliable risk and trend signals. These improved signals enable the agents to make more informed decisions, resulting in stronger performance.
Impact for Simudyne
The architecture described above has been applied to both risk and valuation workflows in Simudyne Horizon, our platform for autonomous financial intelligence. Horizon orchestrates multi-agent systems to construct risk factor models, extract risk signals, and generate structured insights across companies and portfolios. For early access to Simudyne Horizon, sign up to our waiting list here.